Virtualization in usermode
Can we run kernels in userland?
Is it possible to execute a kernel completely in usermode? Well, the short answer seems to be no, as a few issues become immediately apparent.
- How will we execute privileged instructions?
- How will memory be addressed?
However, with a few hacks and tricks, its becomes apparent that there is some possibility. Note that this article assumes the host machine is running Linux on an x86-64 platform, although these concepts still apply to 32-bit programs running on x86-64 systems aswell.
Typically, a host will have a piece of software known as a hypervisor, which runs in kernel mode (arguably a ring below) that allows for virtualization, creating executive environments seperate from your operating system, allowing the user to run other operating systems atop of their own. The question is, can we emulate the behavior of a hypervisor in usermode?
Code execution structure #
Of the current issues present, code execution may be the easiest to address. Most instructions a binary will execute in its lifetime can already be executed without issue in userland. Consider the following example:
; v0 = 0
; while (v0 < 10)
; v0++
function:
push rbp
mov rbp, rsp
mov dword ptr [rbp-4], 0
jmp .L2
.L3:
add dword ptr [rbp-4], 1
.L2:
cmp dword ptr [rbp-4], 9
jle .L3
mov eax, dword ptr [rbp-4]
pop rbp
ret
This snippet (a simple while loop) will execute the same, regardless of whether its executed in user or kernel mode. This gives us an advantage as we won’t need to emulate every instruction in the x86-64 instruction set, giving us a slight performance advantage.
Now, consider this example:
; return __readcr0()
function:
push rbp
mov rbp, rsp
mov rax, cr0
pop rbp
ret
This function will execute just fine in kernel mode, however will trigger the General Protection Exception in usermode, resulting in a segmentation fault (SIGSEGV). Those familiar with debuggers may realize that we can leverage these exceptions to our advantage as we can build a program that will not only catch these exceptions but allow the program to continue instead of crashing. It’s at this stage where emulation is required.
Before we can get into instruction emulation, we have to figure out how exactly we should go about executing our code. One may be quick to think that we can do all the setup and execution in one single process, with a lifetime that looks something like this:
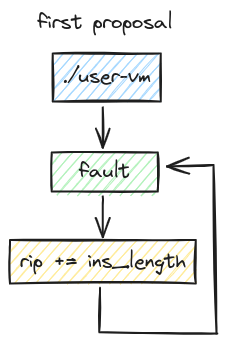
However, this single process architecture becomes limitting quickly. For one, control flows only in one direction, meaning our program practically stuck in an isolated loop (unless a hacky restore point is used). Second, we risk exposing our own memory to the execution, which risks corrupting major components in our program, the most significant of which is the signal handler. Luckily, a more elegant solution exists: fork.

By utilizing fork and ptrace,
(1)Note that neither of these solutions will necessarily grant you the abilty to elegantly switch between 32-bit and 64-bit. Instead of modfying the segment registers, you could use posix_spawn, if needed.
we bring down the risk of corruption significantly as we are able to spawn a clone of our current process, effectively splitting into two. Our forks only task is to signal PTRACE_TRACEME and SIGSTOP, allowing the parent to attach to the child process and begin initialization.
Basic physical memory implementation #
Now that we’ve defined the architecture for our usermode “hypervisor”, we’ve ran into our next issue. How will we address memory? Luckily, we won’t have to emulate most instructions that access memory with mmap.
Shared memory regions can be created using the following:
mmap(address, length, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_SHARED | MAP_ANONYMOUS | MAP_FIXED, -1, 0);
Here, length defines the size of the region in bytes, and address defines the exact address this memory will be mapped to. By utilizing MAP_FIXED, we can effectively map our memory to any address.
An issue may quickly arise however when attempting to map to rather low addresses as /proc/sys/vm/mmap_min_addr will limit the minimum address we can mmap to. Typically, this value will be 65536 (0x10000) and can be verified with the terminal command:
# cat /proc/sys/vm/mmap_min_addr
65536
If we want to map to addresses below 0x10000, you’ll either need to write an implementation within your code to set the value to 0, or alternatively run this command:
# sysctl -w vm.mmap_min_addr="0"
vm.mmap_min_addr = 0
Although we can change the limit of the minimum mappable address, the same cannot be said for the highest address we can map to. The total address space mmap can address is limitted from 0x000000000000 to 0x800000000000, as the userspace can only see these addresses, with addresses above this range being reserved for the kernel. If one wishes to support addresses above this space, MMU emulation is required.
Initialization #
Before splitting the process through forking, we must create a memory map before hand. Upon its creation, the process will fork itself into two. As stated before, the child’s only task during initialization is to signal to parent that the process is ready and tracable. The task of the parent when attaching to the forked process and recieving SIGSTOP is to map any data/executables into memory and set the context accordingly.
Instruction emulation #
Once initialization is over, the parent process will have entered a loop where it will continously call wait(...) and handle each fault. Upon reaching a fault, the parent has to get the current state of the child by obtaining the current state of the registers:
// NT_... defined in linux/elf.h
ptrace(PTRACE_GETREGSET, process, NT_PRSTATUS, &x86_io);
In this code, x86_io is an iovec structure1 pointing to a structure user_regs_struct (defined in sys/user.h), which contains all the registers userland programs have access to.
Because of our memory implementation, we can now read the current instruction with the help of the user_regs_struct structure, accessing eip or rip, completely avoiding ptrace’s PTRACE_PEEKTEXT, PTRACE_PEEKDATA, and PTRACE_PEEKUSER. All we have to do now is to disassemble the instruction at this address, emulate its behavior, add the length of the instruction to the instruction pointer, reset the registers in the child process, and continue.
The reset and continuation can be done in two calls following the handling:
ptrace(PTRACE_SETREGSET, process, NT_PRSTATUS, &x86_io);
ptrace(PTRACE_CONT, process, NULL, NULL);
Additional instruction support #
Typically, if you ever run the instruction cpuid in a virtual machine, it will spit out the hypervisor’s vendor, rather than the host’s vendor (unless modified to not do that). In it’s current state, our program, when executing this instruction, will spit out the host’s result. Changing the result however is relatively simple within the userspace, using the syscall arch_prctl, introduced in Linux 4.12 and supported on Ivy Bridge onwards2.
syscall(SYS_arch_prctl, ARCH_SET_CPUID, NULL);
By calling the syscall using the given code, we can make our fork generate SIGSEGV upon invoking cpuid, giving us full control over its behavior.
This syscall can also be used for getting/setting the FS/GS registers (2)Segment registers often contain critical process data, so modifying them will result in negative side effects. , however may result in undefined behavior as ARCH_SET_GS may be disabled in some kernels and FS already being in use by threading libraries.
Syscall emulation #
As for supporting syscalls without hardcoding predefined ones (meaning the software implements its own syscalls), rdmsr and wrmsr emulation must be used as to support/track the following MSRs3:
| Name | Code | Description |
|---|---|---|
| STAR | 0xC0000081 | Ring 0/3 segment bases, including EIP |
| LSTAR | 0xC0000082 | Entry address for long mode |
| CSTAR | 0xC0000083 | Entry address for compatibility mode |
| SFMASK | 0xC0000084 | Syscall flag mask |
Otherwise, the user may trap the syscall instruction and emulate the behavior using hardcoded syscalls.
16-bit emulation #
An interesting problem that arose when attempting to create a full-fledged virtual machine in usermode was the handling of the initial state of the CPU. All x86 CPUs boot into real mode, a legacy 16-bit mode from the 8086 days with limitted addressing capacity, no memory protection, and no virtual memory4. It’s from this state which processors will either switch to protected mode (32-bits) or long mode (64-bits). For a user who only wishes to execute priveledged code, like a kernel, they can completely ignore this mode. However, for those who wish to build a full fledged virtual machine, this step is crucial in early initialization.
Linux provides the function vm86(...), a system call for a protected mode task to enter VM86 mode (virtual-8086)5. Unfortunately, this syscall is unsupported on x86-64 systems (specifically systems running on an x86-64 kernel).
Although there is a possible workaround involving rebuilding the kernel to enable it6, it would be more of a hassle than required to get the legacy system up and running. Completely emulating real mode before handing over control to the forked process, once a switch has been made, is a much more reliable solution and is relatively inexpensive in terms of performance.
Additional notes #
Another solution using ptrace is to single step through the executing programs. Although this will have a major performance impact when compared to simply executing all instructions and catching faults where we can, this solution may be more practical when it comes to executing just a few instructions while having complete control over syscalls and memory operaitons, easing the way for users to emulate other processor features, most notably virtual memory.